Prev: Linear array notation Next: Expanding array notation
Extended array notation (exAN) is the second part of my array notation.
Definition
First, we need more things to express the notation, mainly separators and layers.
Something
Symbol { is called lbrace, with ASCII = 123 and LaTeX = \{ or \lbrace
Symbol } is called rbrace, with ASCII = 125 and LaTeX = \} or \rbrace
{m1A1m2A2…mk-1Ak-1mk} is a separator, where mi′s are positive integers, Ai′s are separators and k ≥ 1.
In the definition of separators, if k=1, then there’s no Si, so {m} where m is a positive integer is a separator. The simplest separator is {1}, and the comma is just a shorthand for it.
Entries are positive integers separated by separators. Note that there’re entries in arrays, and there’re entries also in separators!
Here’s the definition of layer:
- In array s(m1A1m2A2…mk-1Ak-1mk), all entry mi′s are at base layer, and all separator Ai′s are at layer 1.
- If separator {m1A1m2A2…mk-1Ak-1mk} is at layer n, then all separator Ai′s are at layer n+1.
A more formal definition of separators is:
- {m} is a separator, where m is a positive integer.
- {#Am} is a separator, where m is a positive integer, A is a separator, and # is a string such that {#} is a separator.
And a more formal definition of array is:
- s(a,b) is an array, where a and b are positive integers.
- s(#Am) is an array, where m is a positive integer, A is a separator, and # is a string such that s(#) is an array.
Rules and process
- Rule 1: (base rule – only 2 entries) s(a,b) = a^b
- Rule 2: (recursion rule – neither the 2nd nor 3rd entry is 1) s(a,b,c #) = s(a, s(a,b-1,c #) ,c-1 #)
- Rule 3a: (tailing rule – the last entry is 1) s(# A 1) = s(#)
- Rule 3b: {# A 1} = {#}
- Rule 4: (if lv(A) < lv(B)) {# A 1 B #′} = {# B #′}
where # is a string of entries and separators, it can also be empty. A and B are separators.
If none of the rules above applies, start the process shown below. Note that case B1 and B3 are terminal but case A and B2 are not. First start from the 3rd entry.
- Case A: If the entry is 1, then you jump to the next entry.
- Case B: If the entry n is not 1, look to your left:
- Case B1: If the comma is immediately before you, then
- Change the “1,n” into “b,n-1” where n is this non-1 entry and the b is the iterator.
- Change all the entries at base layer before them into the base.
- The process ends.
- Case B2: If a separator not comma A is immediately before you, then
- Change the “A n” into “A 2 A n-1”
- Jump to the first entry of the former A.
- Case B3: If an lbrace is immediately before you, then
- Change separator {n #} into string Sb, where b is the iterator, S1 = “{n-1 #}” and Si+1 = “Si 1 {n-1 #}”.
- The process ends.
- Case B1: If the comma is immediately before you, then
Levels
We mentioned “lv(A)” above, but what’s it?
The level is a property of separators (actually the arrays also have levels) that can be compared with others, using “<“, “>” and “=”. It’s defined as follows. The level of A is donated by lv(A).
First, all arrays have the lowest and the same level. And note that the same separators have the same level. To compare levels of other separators A and B, we follow these steps.
- Apply rule 3b to A and B until rule 3b cannot apply any more.
- Let A = {a1A1a2A2…ak-1Ak-1ak} and B = {b1B1b2B2…bl-1Bl-1bl}
- If k = 1 and l > 1, then lv(A) < lv(B); if k > 1 and l = 1, then lv(A) > lv(B); if k = l = 1, follow step 4; if k > 1 and l > 1, follow step 5 ~ 10
- If a1 < b1, then lv(A) < lv(B); if a1 > b1, then lv(A) > lv(B); if a1 = b1, then lv(A) = lv(B)
- Let
, and
.
- If lv(AmaxM(A)) < lv(BmaxM(B)), then lv(A) < lv(B); if lv(AmaxM(A)) > lv(BmaxM(B)), then lv(A) > lv(B); or else –
- If |M(A)| < |M(B)|, then lv(A) < lv(B); if |M(A)| > |M(B)|, then lv(A) > lv(B); or else –
- Let A = {#1 AmaxM(A) #2} and B = {#3 BmaxM(B) #4}
- If lv({#2}) < lv({#4}), then lv(A) < lv(B); if lv({#2}) > lv({#4}), then lv(A) > lv(B); or else –
- If lv({#1}) < lv({#3}), then lv(A) < lv(B); if lv({#1}) > lv({#3}), then lv(A) > lv(B); if lv({#1}) = lv({#3}), then lv(A) = lv(B)
Explanation
Rule 1 and 2, and case A are the same as the rules in LAN. Case B1 is a little different, but rule 3b and 4, case B2 and B3 are all new rules.
Rule 4 is unnecessary at this point, but it makes exAN consistent with latter parts.
Dimensional arrays
Dimensional arrays are arrays with separators up to {n} in exAN. Here rule B2 and B3 show their strength.
s(a,b{2}2) is the simplest dimensional array. To solve it, we need to use the process. The 3rd entry is 2, and there’s a separator not comma {2} immediately before the 2, so we meet case B2. Now change the array into s(a,b{2}2{2}1), then restart the process from the first entry in the former {2}. It’s 2 not 1, and an lbrace is immediately before the 2, so we meet case B3. Now change the {2} into {1}1{1}1…{1}1{1} with b {1}’s, so s(a,b{2}2) = s(a,b{1}1{1}1…{1}1{1}2{2}1) (with b {1}’s)= s(a,b,1,1…,1,2) with b-1 1’s (apply rule 3, and note that {1} is the comma) = s(a,a,a,…a,b) (with b a’s).
Unlike BEAF and BAN, in this array notation, s(a,b{2}2), s(a,b,1{2}2) and s(a,b,1,1{2}2) are not the same. They’re s(a,b,1,1…,1,2) with b-1, b and b+1 1’s respectively.
s(a,b{2}3) = s(a,b,1,1…,1,2{2}2) with b-1 1’s, when it reduces to s(a,b’,1,1…,1,1{2}2) , it becomes s(a,b’,1,1…,1,1,2) with b’+b-1 1’s. At most situations, b is nothing comparing to b’, so the remaining entries (the b 1’s remaining in s(a,b’,1,1…,1,1{2}2)) don’t affect the strength of the notation.
Some more examples,
s(a,b{2}1{2}2) = s(a,b{2}1,1…,1,2) (with b-1 1’s)= s(a,a{2}a,a…,a,b) (with b-2 a’s after the {2})
s(a,b{2}1{2}c) = s(a,b{2}1,1…,1,2{2}c-1) (with b-1 1’s)
s(a,b{c}d) = s(a,b{c-1}1{c-1}1…{c-1}1{c-1}2{c}d-1) (with b {c-1}’s)
Rule 3b and case B1
This two rules allow us to go further.
For example, to solve s(a,b{1,2}2), we start the process, and meet case B2, then the array becomes s(a,b{1,2}2{1,2}1). Then we restart the process from the 1 in the former {1,2}, and meet case B1, so change the “1,2” into “b,1”, and change the entries at base layer into a. So s(a,b{1,2}2) = s(a,a{b,1}2{1,2}1). Now rule 3a applies, so s(a,a{b,1}2{1,2}1) = s(a,a{b,1}2), then rule 3b applies, so s(a,a{b,1}2) = s(a,a{b}2). As a result, we can have more than 1 entries inside a separator.
To solve s(a,b{1{2}1,2}2), we start the process, then meet case B2, then meet case B1. Before case B1 applies, the array is s(a,b{1{2}1,2}2{1{2}1,2}1); after case B1 applies, the array becomes s(a,a{1{2}b,1}2{1{2}1,2}1). Then rule 3a and 3b applies, so s(a,b{1{2}1,2}2) = s(a,a{1{2}b}2). What if we use the case B1 in Linear array notation? s(a,b{1{2}1,2}2) will be s(a,a{a{a}b}2). When a ≥ 3 and b ≥ 2, it’ll reduces to something containing {1{2}1,2} again – it can never be solved. So a change on case B1 is necessary.
Comparison
Here’re some comparisons between exAN and FGH (growth rate).
s(n,n{2}2) has growth rate
s(n,n,2{2}2) has growth rate
s(n,n,3{2}2) has growth rate
s(n,n,1,2{2}2) has growth rate
s(n,n,2,2{2}2) has growth rate
s(n,n,1,3{2}2) has growth rate
s(n,n,1,4{2}2) has growth rate
s(n,n,1,1,2{2}2) has growth rate
s(n,n,2,1,2{2}2) has growth rate
s(n,n,1,2,2{2}2) has growth rate
s(n,n,1,1,3{2}2) has growth rate
s(n,n,1,1,1,2{2}2) has growth rate
s(n,n,1,1…,1,2{2}2) with m 1’s has growth rate
s(n,n{2}3) has growth rate
s(n,n,2{2}3) has growth rate
s(n,n,1,2{2}3) has growth rate
s(n,n,1,1,2{2}3) has growth rate
s(n,n,1,1,1,2{2}3) has growth rate
s(n,n{2}4) has growth rate
s(n,n{2}1,2) = s(n,n{2}n) has growth rate
s(n,n,2{2}1,2) has growth rate
s(n,n,1,2{2}1,2) has growth rate
s(n,n{2}2,2) has growth rate
s(n,n{2}3,2) has growth rate
s(n,n{2}1,3) has growth rate
s(n,n{2}1,4) has growth rate
s(n,n{2}1,1,2) has growth rate
s(n,n{2}2,1,2) has growth rate
s(n,n{2}1,2,2) has growth rate
s(n,n{2}1,1,3) has growth rate
s(n,n{2}1,1,1,2) has growth rate
s(n,n{2}1,1,1,1,2) has growth rate
s(n,n{2}1{2}2) has growth rate
s(n,n,2{2}1{2}2) has growth rate
s(n,n{2}2{2}2) has growth rate
s(n,n{2}1,2{2}2) has growth rate
s(n,n{2}1,1,2{2}2) has growth rate
s(n,n{2}1{2}3) has growth rate
s(n,n{2}1{2}1,2) has growth rate
s(n,n{2}1{2}1,1,2) has growth rate
s(n,n{2}1{2}1{2}2) has growth rate
s(n,n{2}1{2}1{2}1{2}2) has growth rate
s(n,n{3}2) has growth rate
s(n,n,2{3}2) has growth rate
s(n,n{2}2{3}2) has growth rate
s(n,n{2}1,2{3}2) has growth rate
s(n,n{2}1{2}2{3}2) has growth rate
s(n,n{2}1{2}1{2}2{3}2) has growth rate
s(n,n{3}3) has growth rate
s(n,n{3}1,2) has growth rate
s(n,n{3}1{2}2) has growth rate
s(n,n{3}1{2}1{2}2) has growth rate
s(n,n{3}1{3}2) has growth rate
s(n,n{3}1{3}1{3}2) has growth rate
s(n,n{4}2) has growth rate
s(n,n{5}2) has growth rate
s(n,n{1,2}2) has growth rate 
s(n,n,2{1,2}2) has growth rate
s(n,n{2}2{1,2}2) has growth rate
s(n,n{3}2{1,2}2) has growth rate
s(n,n{4}2{1,2}2) has growth rate
s(n,n{1,2}3) has growth rate
s(n,n{1,2}1,2) has growth rate
s(n,n{1,2}1{2}2) has growth rate
s(n,n{1,2}1{3}2) has growth rate
s(n,n{1,2}1{4}2) has growth rate
s(n,n{1,2}1{1,2}2) has growth rate
s(n,n{1,2}1{1,2}1{1,2}2) has growth rate
s(n,n{2,2}2) has growth rate
s(n,n{2,2}3) has growth rate
s(n,n{2,2}1,2) has growth rate
s(n,n{2,2}1{1,2}2) has growth rate
s(n,n{2,2}1{1,2}1{1,2}2) has growth rate
s(n,n{2,2}1{2,2}2) has growth rate
s(n,n{2,2}1{2,2}1{2,2}2) has growth rate
s(n,n{3,2}2) has growth rate
s(n,n{3,2}1{3,2}2) has growth rate
s(n,n{4,2}2) has growth rate
s(n,n{1,3}2) has growth rate
s(n,n{2,3}2) has growth rate
s(n,n{3,3}2) has growth rate
s(n,n{1,4}2) has growth rate
s(n,n{1,1,2}2) has growth rate
s(n,n{1,1,2}3) has growth rate
s(n,n{1,1,2}1,2) has growth rate
s(n,n{1,1,2}1{1,1,2}2) has growth rate
s(n,n{2,1,2}2) has growth rate
s(n,n{1,2,2}2) has growth rate
s(n,n{1,1,3}2) has growth rate
s(n,n{1,1,1,2}2) has growth rate
s(n,n{1{2}2}2) has growth rate 
s(n,n{1{2}2}3) has growth rate
s(n,n{1{2}2}1{1{2}2}2) has growth rate
s(n,n{2{2}2}2) has growth rate
s(n,n{1,2{2}2}2) has growth rate
s(n,n{1{2}3}2) has growth rate
s(n,n{1{2}1,2}2) has growth rate
s(n,n{1{2}1{2}2}2) has growth rate
s(n,n{1{3}2}2) has growth rate
s(n,n{1{4}2}2) has growth rate
s(n,n{1{1,2}2}2) has growth rate
s(n,n{1{1{2}2}2}2) has growth rate
s(n,n{1{1{1,2}2}2}2) has growth rate









































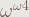



























































Function f(n) = s(n,n{1{1…{1{1,2}2}…2}2}2) (with n 2’s) eventually outgrows any expression in exAN, so it has growth rate 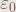
- Goodstein function
- Kirby-Paris hydra function
- Beklemishev’s worm function
- Friedman’s circle function
- tetrational array in BEAF (i.e. n^^n&n)
- nested array notation in BAN (i.e. {n,n[1[1…[1,2]…2]2]2} with n 2’s)
- cascading-E notation (i.e. En#^#^…#^#n with n #’s)

Did you forgot this? ‘A 1 B’ reduces into ‘B’, if B > A.
LikeLike
No such rule. Also, the absence of this rule makes (m)△ in NDAN not identical from m-ple comma in DAN.
LikeLike
If the strong array notation works, that will be faster than BAN arrays, s(a,b{2}4) is even higher.
LikeLike
We how about to learn superdimensional arrays.
{a, b [1, 2] 2} = s(a,b{1,2}2)
{a, b [1, 3] 2} = s(a,b{1,3}2)
{a, b [1, 4] 2} = s(a,b{1,4}2)
{a, b [1, 1, 2] 2} = s(a,b{1,1,2}2)
{a, b [1, 1, 1, 2] 2} = s(a,b{1,1,1,2}2)
etc.
BAN, BEAF same as exAN.
{a, b [1 [2] 2] 2} = s(a,b{1{2}2}2)
{a, b [2 [2] 2] 2} = s(a,b{2{2}2}2)
{a, b [1 [2] 3] 2} = s(a,b{1{2}3}2)
{a, b [1 [2] 1, 2] 2} = s(a,b{1{2}1, 2}2)
{a, b [1 [2] 1 [2] 2] 2} = s(a,b{1{2}1{2}2}2)
{a, b [1 [1, 2] 2] 2} = s(a,b{1{1,2}2}2)
{a, b [1 [1 [2] 2] 2] 2} = s(a,b{1{1{2}2}2}2)
And all the way to limit of exAN.
That’s all for tutorial.
LikeLike
Limit of exAN is s(10,100{1{1…2}2}2) (with 49 curly brackets inside)
LikeLike
Hi famingtoading
LikeLike
Number names in superdimensional arrays in exAN:
s(10,100{1,2}2) – Gongulus
s(10,100{1,3}2) – Gingulus
s(10,100{1,4}2) – Gangulus
s(10,100{1,5}2) – Geengulus
s(10,100{1,6}2) – Gowngulus
s(10,100{1,7}2) – Gungulus
s(10,100{1,1,2}2) – Bongulus
s(10,100{1,1,3}2) – Bingulus
s(10,100{1,1,4}2) – Bangulus
s(10,100{1,1,5}2) – Beengulus
s(10,100{1,1,1,2}2) – Trongulus
s(10,100{1{2}2}2) – Goplexulus
s(10,100{1{1,2}2}2) – Goduplexulus
s(10,100{1{1{2}2}2}2) – Gotriplexulus
s(10,100{1`2}2) – Goppatoth (Limit of exAN)
LikeLike
Hi
LikeLike
Sup
LikeLike
Famingtoading unkind. Can
LikeLike