Prev: Dropping array notation Next: Dropper-expanding notation
Note: this version of the notation doesn’t work.
Nested dropper array notation (NDAN) is the eighth part of my array notation. In this part, the definition will change a lot.
Symbol △ is called triangle, with unicode = 9651 and LaTeX = \triangle
Symbol ○ is called circle, with unicode = 9675 and LaTeX = \circ
Let the triangle be a high-leveled separator. And we use a pair of parentheses to be a prefix of separators. If A is a separator, then we can have (m)A for some A, where m is a positive integer.
(1)A is a 1-separator, (2)A is a 2-separator, (3)A is a 3-separator, and so on. When this prefix is applied on the triangle, then (1)△ is the grave accent – the least 1-separator, (2)△ is the double comma – the least 2-separator, (3)△ is the triple comma – the least 3-separator, and so on.
In DAN, the (m)-separator (m)△ solves in this way: Search out for a separator Au(m) that has lower level than it, then Bu(m) becomes (m-1)Bu(m). As a (m-1)-separator, the (m-1)Bu(m) search out for a separator Au(m-1) that has lower level than it. If it has lower level than “X Y” (where (m-1)Bu(m) = “X (m)Bu(m+1) 2 Y” = “X (m)△ 2 Y”), then add “X Y” somewhere inside Bu(m-1). Or Bu(m-1) becomes (m-2)Bu(m-1). Continue downward, until (1)Bu(2). Finally Bu(1) = “P (1)Bu(2) Q”, then it expands.
So, an (m)A drops down to (m-1)B, and {P (1)A Q} expands. So the ()-prefix is called dropper. But in DAN, all the dropping process are inside one rule, and it can just drop finite times, meaning that we cannot have (1,2) dropper, (1`2) dropper, etc. In NDAN, we can because the “case B2” is separated into several parts. The “1,2” in (1,2)A reduces in normal comma way, and the “1`2” in (1`2)A reduces in normal way (just search out, it doesn’t matter if you’re inside a dropper).
Next, let the circle be a high-leveled dropper. We can have (1(1)△2)△ = (1`2)△, (1(2)△2)△ = (1,,2)△, (1(3)△2)△ = (1,,,2)△, (1(1,2)△2)△, (1(1(1,2)△2)△2)△, and so on. ○△ is a high-leveled separator, and (2)○△ is the 1-separator of ( ____ )△ – it’s the least 1-separator in a dropper! If A is a dropper and B is a no-prefixed separator, then (1)AB is a 1-separator of dropper, (2)AB is a 2-separator of dropper, etc. If A and B are droppers, C is a no-prefixed separator, then (1)ABC is a 1-separator of dropper of dropper, (2)ABC is a 2-separator of dropper of dropper. And (1)○○○△, (1)○○○○△, etc. – all these lead to the full nested dropper array notation.
Definition
Syntax:
- s(a,b) is an array where a and b are positive integers.
- s(#Am) is an array, where m is a positive integer, A is a separator, and # is a string such that s(#) is an array.
Definition of separators:
- The m-ple comma (,,…,) with m ≥ 2 are separators. (basic separators)
- {m} is a separator, where m is a positive integer.
- {#Am} is a separator, where m is a positive integer, A is a separator, and # is a string such that {#} is a separator.
- AB is a separator, where A is a dropper and B is a separator.
Definition of droppers:
- The ○ is a dropper.
- (m) is a dropper, where m is a positive integer.
- (#Am) is a dropper, where m is a positive integer, A is a separator, and # is a string such that (#) is a dropper.
Note:
- The comma (,) is a shorthand for {1}.
- The grave accent ` = (1)△, the double comma ,, = (2)△, the triple comma ,,, = (3)△, and so on, the m-ple comma ,,…, = (m)△ where m ≥ 2.
- When a separator A = A1A2…Ak-1Ak, where A1, A2, …, Ak-1 are dropper and Ak is a single separator (not jointed by a dropper and a separator), we say A1, A2, …, Ak-1, Ak are sections in separator A.
Rules and process
- Rule 1: (base rule – only 2 entries) s(a,b) = a^b
- Rule 2a: (tailing rule – the last entry is 1) s(# A 1) = s(#), {# A 1} = {#} and (# A 1) = (#)
- Rule 3: (recursion rule – neither the 2nd nor 3rd entry is 1) s(a,b,c #) = s(a, s(a,b-1,c #) ,c-1 #)
where # is a string of entries and separators, it can also be empty. A is a separator.
If none of the 3 rules above applies, start the process shown below. Note that case B1, B2, B4 and B5 are terminal but case A and B3 are not. b, n, M, Bt′s and K are parts of the original array but t, i, Si, At′s, P and Q are not. Before we start, let A0 be the whole array. First start from the 3rd entry.
- Case A: If the entry is 1, then you jump to the next entry.
- Case B: If the entry n is not 1, look to your left:
- Case B1: If the comma is immediately before you, then
- Change the “1,n” into “b,n-1” where n is this non-1 entry and the b is the iterator.
- Change all the entries at base layer before them into the base.
- The process ends.
- Case B2: If a separator (1)M (where M is the remaining sections) is immediately before you, then
- Let t be such that the (1)M is are layer t. And let B0 be the whole array now.
- Repeat this:
- Subtract t by 1.
- Let separator Bt be such that it’s at layer t, and the (1)M is inside it.
- If t = 1, then break the repeating, or else continue repeating.
- Find the maximum of t such that lv(At) < lv((1)M).
- If lv(At) < lv(D(M)), then
- Find the minimum of v such that v > t and lv(Av) < lv(U(M)).
- Let string P and Q be such that Bt = “P Bv Q”.
- Change Bt into “P X(M) Av Y(M) Q”.
- The process ends.
- If lv(At) ≥ lv(D(M)), then
- Let string P and Q be such that Bt = “P (1)M n Q”.
- Change Bt into Sb, where b is the iterator, S1 is comma, and Si+1 = “P Si 2 (1)M n-1 Q”.
- The process ends.
- Case B3: If a separator K is immediately before you, and it doesn’t fit case B1 or B2, then
- Change the “K n” into “K 2 K n-1”.
- Set separator At = K, here K is at layer t.
- Jump to the first entry of the former K.
- Case B4: If an lbrace is immediately before you, then
- Change separator {n #} into string Sb, where b is the iterator, S1 = “{n-1 #}” and Si+1 = “Si 1 {n-1 #}”.
- The process ends.
- Case B5: If a “(” is immediately before you, then
- Let t be such that the separator (n #)M is are layer t, here (n #) is the first section and M is the remaining sections. And let B0 be the whole array now.
- Repeat this:
- Subtract t by 1.
- Let separator Bt be such that it’s at layer t, and the (n #)M is inside it.
- If t = 1, then break the repeating, or else continue repeating.
- Find the maximum of t such that lv(At) < lv((n #)M).
- If lv(At) < lv(D(M)), then
- Find the minimum of v such that v > t and lv(Av) < lv(U(M)).
- Let string P and Q be such that Bt = “P Bv Q”.
- Change Bt into “P X(M) Av Y(M) Q”.
- The process ends.
- If lv(At) ≥ lv(D(M)), then
- Change Bt into “(n-1 #)At“.
- The process ends.
- Case B1: If the comma is immediately before you, then
Level comparison
All arrays have the lowest and the same level. Then the “+” has the highest level, the triangle has the second highest level. And note that the same separators have the same level. To compare levels of other separators A and B, we follow these steps.
- Compare levels of the last section of A and B using normal rules. If lv(last section of A) < lv(last section of B), then lv(A) < lv(B); if lv(last section of A) > lv(last section of B), then lv(A) > lv(B); or else –
- If A has only 1 section but B has more than 1 sections, then lv(A) > lv(B); if A has more than 1 sections but B has only 1 section, then lv(A) < lv(B); if both A and B have only 1 section, then lv(A) = lv(B); or else –
- Let A = “#1 (P) M” where M is the last section and (P) is the second last section, B = “#2 (Q) N” where N is the last section and (Q) is the second last section.
- If lv(“#1 {P}”) < lv(“#2 {Q}”), then lv(A) < lv(B); if lv(“#1 {P}”) > lv(“#2 {Q}”), then lv(A) > lv(B); if lv(“#1 {P}”) = lv(“#2 {Q}”), then lv(A) = lv(B). Note that if (P) (or (Q)) is the circle, then {P} (or {Q}) is the triangle.
Normal rules:
- Apply rule 2 to A and B until rule 2 cannot apply any more.
- Let A = {a1A1a2A2…ak-1Ak-1ak} and B = {b1B1b2B2…bl-1Bl-1bl}
- If k = 1 and l > 1, then lv(A) < lv(B); if k > 1 and l = 1, then lv(A) > lv(B); if k = l = 1, follow step 4; if k > 1 and l > 1, follow step 5 ~ 10
- If a1 < b1, then lv(A) < lv(B); if a1 > b1, then lv(A) > lv(B); if a1 = b1, then lv(A) = lv(B)
- Let
, and
.
- If lv(AmaxM(A)) < lv(BmaxM(B)), then lv(A) < lv(B); if lv(AmaxM(A)) > lv(BmaxM(B)), then lv(A) > lv(B); or else –
- If |M(A)| < |M(B)|, then lv(A) < lv(B); if |M(A)| > |M(B)|, then lv(A) > lv(B); or else –
- Let A = {#1 AmaxM(A) #2} and B = {#3 BmaxM(B) #4}
- If lv({#2}) < lv({#4}), then lv(A) < lv(B); if lv({#2}) > lv({#4}), then lv(A) > lv(B); or else –
- If lv({#1}) < lv({#3}), then lv(A) < lv(B); if lv({#1}) > lv({#3}), then lv(A) > lv(B); if lv({#1}) = lv({#3}), then lv(A) = lv(B)
Subfunctions
4 subfunctions appear in the process: U, D, X and Y function. The inputs of them are separators, the outputs of U and D are separators, and the outputs of X and Y are strings.
The primitive definitions of U, D, X and Y are as follows. If A = ○○…○△ (there also can be no circles), then
- U(A) = “+”
- D(A) = “,”
- X(A) = “{1”
- Y(A) = “2}”
For other A such that the first section of A is neither △ nor ○, U(A), D(A), X(A) and Y(A) are determined in those steps:
- Start the process, and start from the first entry of B. But we use case A, B3 and B5 only. Until we meet case B5.
- When we meet case B5, don’t go into it. Let string P and Q be such that A = “P (n #)M 2 Q”.
- Define U(A) = “(n #)M”, D(A) = “P Q”, X(A) = “P” and Y(A) = “2 Q”.
Explanation
In the process, the case B2 is the dropping and expanding of 1-separators. The case B5 is the dropping of higher-separators. The four functions, U, D, X and Y are the linking between different “drop down process”.
Since U(○○…○△) = “+”, when it drops in case B5, and we jump into step 4, “lv(Av) < lv(U(M))” is always true, so v = t+1.
Pay attention to the step 2 of the 4 new rules in level comparisons. It means that “(P)M” always have lower level than M. In step 5 of case B5 in the process, the Bt becomes “(n-1 #)At“, so the level of it reduces.
Since we separate the dropping process into several parts, we’ll meet case B3 more often. Every time we meet case B3, it pulls the K out, so NDAN is not exactly the same as DAN even below (1,2)△. The simplest example, s(a,b{1{1(2)△2}3}2) = s(a,b{1(1){1(2)△2}2{1(2)△2}2}2) = s(a,b{1…{1{1,2(1){1(2)△2}1{1(2)△2}2}2(1){1(2)△2}1{1(2)△2}2}…2(1){1(2)△2}1{1(2)△2}2}2) with b-1 (1){1(2)△2}′s. After many steps, s(a,b{1(1){1(2)△2}1{1(2)△2}2}2) = s(a,b{1(1){1(2)△2}1(1){1(2)△2}2{1(2)△2}1}2) = s(a,b{1(1){1(2)△2}1(1){1(2)△2}2}2), and it has growth rate 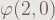


How nDAN doesn’t work?
Why doesn’t work beyond psi function?
LikeLike