Prev: Dropping array notation Next: Weak dropper-expanding notation
Nested dropper array notation (NDAN) is the eighth part of my array notation. In this part, the definition will change a lot.
Symbol △ is called triangle, with unicode = 9651 and LaTeX = \triangle
Symbol ○ is called circle, with unicode = 9675 and LaTeX = \circ
Let the triangle be a high-leveled separator. And we use a pair of parentheses to be a prefix of separators. If A is a separator, then we can have (m)A for some A, where m is a positive integer.
(1)A is a 1-separator, (2)A is a 2-separator, (3)A is a 3-separator, and so on. When this prefix is applied on the triangle, then (1)△ is the grave accent – the least 1-separator, (2)△ is the double comma – the least 2-separator, (3)△ is the triple comma – the least 3-separator, and so on.
In DAN, the (m)-separator (m)△ solves in this way: Search out for a separator Au(m) that has lower level than it, then Bu(m) becomes (m-1)Bu(m). As a (m-1)-separator, the (m-1)Bu(m) search out for a separator Au(m-1) that has lower level than it. If it has lower level than “X Y” (where (m-1)Bu(m) = “X (m)Bu(m+1) 2 Y” = “X (m)△ 2 Y”), then add “X Y” somewhere inside Bu(m-1). Or Bu(m-1) becomes (m-2)Bu(m-1). Continue downward, until (1)Bu(2). Finally Bu(1) = “P (1)Bu(2) Q”, then it expands.
So, an (m)A drops down to (m-1)B, and {P (1)A Q} expands. So the ()-prefix is called dropper. But in DAN, all the dropping process are inside one rule, and it can just drop finite times, meaning that we cannot have (1,2) dropper, (1`2) dropper, etc. In NDAN, we can because the “case B2” is separated into several parts. The “1,2” in (1,2)A reduces in normal comma way, and the “1`2” in (1`2)A reduces in normal way (just search out; it doesn’t matter if you’re inside a dropper).
Next, let the circle be a high-leveled dropper. We can have (1(1)△2)△ = (1`2)△, (1(2)△2)△ = (1,,2)△, (1(3)△2)△ = (1,,,2)△, (1(1,2)△2)△, (1(1(1,2)△2)△2)△, and so on. ○△ is a high-leveled separator, and (1)○△ is the 1-separator of ( ____ )△ – it’s the least 1-separator in a dropper! If A is a dropper and B is a no-prefixed separator, then (1)AB is a 1-separator of dropper, (2)AB is a 2-separator of dropper, etc. If A and B are droppers, C is a no-prefixed separator, then (1)ABC is a 1-separator of dropper of dropper, (2)ABC is a 2-separator of dropper of dropper. And (1)○○○△, (1)○○○○△, etc. – all these lead to the full nested dropper array notation.
Definition
Syntax:
- s(a,b) is an array where a and b are positive integers.
- s(#Am) is an array, where m is a positive integer, A is a separator, and # is a string such that s(#) is an array.
Definition of separators:
- The △ is a separator.
- {m} is a separator, where m is a positive integer.
- {#Am} is a separator, where m is a positive integer, A is a separator, and # is a string such that {#} is a separator.
- AB is a separator, where A is a dropper and B is a separator.
Definition of droppers:
- The ○ is a dropper.
- (m) is a dropper, where m is a positive integer.
- (#Am) is a dropper, where m is a positive integer, A is a separator, and # is a string such that (#) is a dropper.
Note:
- The comma (,) is a shorthand for {1}.
- The grave accent in DAN corresponds to (1)△, the double comma corresponds to (2)△, the triple comma corresponds to (3)△, and so on.
- When a separator A = A1A2…Ak-1Ak, where A1, A2, …, Ak-1 are dropper and Ak is a single separator (not jointed by a dropper and a separator), we say A1, A2, …, Ak-1, Ak are sections in separator A. Define F(A) to be the first section of A, with (#) changed into {#}.
Rules and process
- Rule 1: (base rule – only 2 entries) s(a,b) = a^b
- Rule 2: (tailing rule – the last entry is 1) s(# A 1) = s(#), {# A 1} = {#} and (# A 1) = (#)
- Rule 3: (recursion rule – neither the 2nd nor 3rd entry is 1) s(a,b,c #) = s(a, s(a,b-1,c #) ,c-1 #)
where # is a string of entries and separators, it can also be empty. A is a separator.
If none of the 3 rules above applies, start the process shown below. Note that case B1, B2, B4 and B5 are terminal but case A and B3 are not. b, n, M, Bt′s and K are parts of the original array but t, i, Si, At′s, P and Q are not. Before we start, let A0 and F(A0) be the whole array. First start from the 3rd entry.
- Case A: If the entry is 1, then you jump to the next entry.
- Case B: If the entry n is not 1, look to your left:
- Case B1: If the comma is immediately before you, then
- Change the “1,n” into “b,n-1” where n is this non-1 entry and the b is the iterator.
- Change all the entries at base layer before them into the base.
- The process ends.
- Case B2: If a separator (1)M (where M is the remaining sections) is immediately before you, then
- Let t be such that the (1)M is are layer t. And let B0 be the whole array now.
- Repeat this:
- Subtract t by 1.
- Let separator Bt be such that it’s at layer t, and the (1)M is inside it.
- If t = 1, then break the repeating, or else continue repeating.
- Find the maximum of t such that lv(At) < lv((1)M).
- If lv(F(At)) < lv(D(F(M))), then
- Find the minimum of v such that v > t and lv(Av) < lv(U(M)).
- Let string P and Q be such that Bt = “P Bv Q”.
- Change Bt into “P X(M) Av Y(M) Q”.
- The process ends.
- If lv(F(At)) ≥ lv(D(F(M))), then
- Let string P and Q be such that Bt = “P (1)M n Q”.
- Change Bt into Sb, where b is the iterator, S1 is comma, and Si+1 = “P Si 2 (1)M n-1 Q”.
- The process ends.
- Case B3: If a separator K is immediately before you, and it doesn’t fit case B1 or B2, then
- Change the “K n” into “K 2 K n-1”.
- Set separator At = K, here K is at layer t.
- Jump to the first entry of the former K.
- Case B4: If an lbrace is immediately before you, then
- Change separator {n #} into string Sb, where b is the iterator, S1 = “{n-1 #}” and Si+1 = “Si 1 {n-1 #}”.
- The process ends.
- Case B5: If a “(” is immediately before you, then
- Let t be such that the separator (n #)M is are layer t, here (n #) is the first section and M is the remaining sections. And let B0 be the whole array now.
- Repeat this:
- Subtract t by 1.
- Let separator Bt be such that it’s at layer t, and the (n #)M is inside it.
- If t = 1, then break the repeating, or else continue repeating.
- Find the maximum of t such that lv(At) < lv((n #)M).
- If lv(F(At)) < lv(D(F(M))), then
- Find the minimum of v such that v > t and lv(Av) < lv(U(M)).
- Let string P and Q be such that Bt = “P Bv Q”.
- Change Bt into “P X(M) Av Y(M) Q”.
- The process ends.
- If lv(F(At)) ≥ lv(D(F(M))), then
- Change Bt into “(n-1 #)At“.
- The process ends.
- Case B1: If the comma is immediately before you, then
Level comparison
All arrays have the lowest and the same level. Then the “:” has the highest level, the triangle has the second highest level. And note that the same separators have the same level. To compare levels of other separators A and B, we follow these steps.
- Compare levels of the last section of A and B using normal rules. If lv(last section of A) < lv(last section of B), then lv(A) < lv(B); if lv(last section of A) > lv(last section of B), then lv(A) > lv(B); or else –
- If A has only 1 section but B has more than 1 sections, then lv(A) > lv(B); if A has more than 1 sections but B has only 1 section, then lv(A) < lv(B); if both A and B have only 1 section, then lv(A) = lv(B); or else –
- Let A = “#1 (P) M” where M is the last section and (P) is the second last section, B = “#2 (Q) N” where N is the last section and (Q) is the second last section.
- If lv(“#1 {P}”) < lv(“#2 {Q}”), then lv(A) < lv(B); if lv(“#1 {P}”) > lv(“#2 {Q}”), then lv(A) > lv(B); if lv(“#1 {P}”) = lv(“#2 {Q}”), then lv(A) = lv(B). Note that if (P) (or (Q)) is the circle, then {P} (or {Q}) is the triangle.
Normal rules:
- Apply rule 2 to A and B until rule 2 cannot apply any more.
- Let A = {a1A1a2A2…ak-1Ak-1ak} and B = {b1B1b2B2…bl-1Bl-1bl}
- If k = 1 and l > 1, then lv(A) < lv(B); if k > 1 and l = 1, then lv(A) > lv(B); if k = l = 1, follow step 4; if k > 1 and l > 1, follow step 5 ~ 10
- If a1 < b1, then lv(A) < lv(B); if a1 > b1, then lv(A) > lv(B); if a1 = b1, then lv(A) = lv(B)
- Let
, and
.
- If lv(AmaxM(A)) < lv(BmaxM(B)), then lv(A) < lv(B); if lv(AmaxM(A)) > lv(BmaxM(B)), then lv(A) > lv(B); or else –
- If |M(A)| < |M(B)|, then lv(A) < lv(B); if |M(A)| > |M(B)|, then lv(A) > lv(B); or else –
- Let A = {#1 AmaxM(A) #2} and B = {#3 BmaxM(B) #4}
- If lv({#2}) < lv({#4}), then lv(A) < lv(B); if lv({#2}) > lv({#4}), then lv(A) > lv(B); or else –
- If lv({#1}) < lv({#3}), then lv(A) < lv(B); if lv({#1}) > lv({#3}), then lv(A) > lv(B); if lv({#1}) = lv({#3}), then lv(A) = lv(B)
Subfunctions
4 subfunctions appear in the process: U, D, X and Y function. The inputs of them are separators, the outputs of U and D are separators, and the outputs of X and Y are strings.
When calculating U, D, X and Y function on △ or ○○…○△, we see △ as {1:2}, see ○ as (1:2), where : is the highest-leveled separator.
For a separator A, U(A), D(A), X(A) and Y(A) are determined as follows. Start the subprocess shown below. Process start from the first entry of A. Note that case B1 and B3 give definitions but case A and B2 don’t.
- Case A: If the entry is 1, then you jump to the next entry.
- Case B: If the entry n is not 1, look to your left:
- Case B1: If the “:” is immediately before you, then
- Let string P and Q be such that A = “P : 2 Q”.
- Define U(A) = “:”, D(A) = “P Q”, X(A) = “P” and Y(A) = “2 Q”.
- Case B2: If a separator K not the “:” is immediately before you, then
- Change the “K n” into “K 2 K n-1”.
- Jump to the first entry of the former K.
- Case B3: If the “(” is immediately before you, then
- Let string P and Q be such that A = “P (n #)M 2 Q”, where (n #)M is the separator.
- Define U(A) = “(n #)M”, D(A) = “P Q”, X(A) = “P” and Y(A) = “2 Q”.
- Case B1: If the “:” is immediately before you, then
Explanation
In the process, the case B2 is the dropping and expanding of 1-separators. The case B5 is the dropping of higher-separators. The four functions, U, D, X and Y are the linking between different “drop down process”.
Pay attention to the step 2 of the 4 new rules in level comparisons. It means that “(P)M” always have lower level than M. In step 5 of case B5 in the process, the Bt becomes “(n-1 #)At“, so the level of it reduces.
Since we separate the dropping process into several parts, we’ll meet case B3 more often. Every time we meet case B3, it pulls the K out, so NDAN is not exactly the same as DAN even below (1,2)△. The simplest example, s(a,b{1{1(2)△2}3}2) = s(a,b{1(1){1(2)△2}2{1(2)△2}2}2) = s(a,b{1…{1{1,2(1){1(2)△2}1{1(2)△2}2}2(1){1(2)△2}1{1(2)△2}2}…2(1){1(2)△2}1{1(2)△2}2}2) with b-1 (1){1(2)△2}′s. After many steps, s(a,b{1(1){1(2)△2}1{1(2)△2}2}2) = s(a,b{1(1){1(2)△2}1(1){1(2)△2}2{1(2)△2}1}2) = s(a,b{1(1){1(2)△2}1(1){1(2)△2}2}2), and it has growth rate 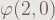

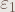
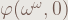
We use F(At) and D(F(M)) instead of At and D(M) in the process, and that’s the main difference from the old version. In the old version, some expressions cause infinity loop, and they make the notation fail.
For example, let A1 be dropper (1(2)○△2) and B1 be separator △, then D(A1B1) = (1)B1. For dropper An and separator Bn such that D(AnBn) = (1)Bn, the separator {1(2(1)AnBn2)Bn2} reduces to (1(1)AnBn2){1(2(1)AnBn2)Bn2}, which reduces to (1(1(1)AnBn2)Bn2){1(2(1)AnBn2)Bn2}, which reduces to (1(1…(1(1,2)Bn2)Bn…2)Bn2){1(2(1)AnBn2)Bn2}, which reduces to (1(3)Bn2)C after many steps, which reduces to {1(2(2)Bn2)D3} after many steps, which reduces to {1(2(1)(2(2)Bn2)E2)E2} after many steps. Note that there’re some △′s inside E, so lv(E) > lv({1E2}) > lv({1(2(1)(2(2)Bn2)E2)E2}). Now let An+1 be (2(2)Bn2) and Bn+1 be the E, then it becomes {1(2(1)An+1Bn+12)Bn+12}, and D(An+1Bn+1) = (1)Bn+1. This pattern can repeat infinitely, so {1(2(1)(1(2)○△2)△2)△2} can never be solved, and so are (2(2)○△2)△ and (1)○○△.
So we must change, to make NDAN well-defined.
Doesn’t work
(Updated at Oct 18, 2017)
This version of NDAN still doesn’t work due to this infinite loop.
Let X1 be string “{1” and Y1 be “2}”, X(n+1) = “X1 Xn” and Y(n+1) = “Yn Y1”. Separator “Xn Xn (1,2)△ Yn 2 (1,2)△ Yn” first reduces to “Xn Xn (b)△ Yn 2 Xn (1,2)△ Yn 1 (1,2)△ Yn”, then “Xn X(n-1) (b-1){1 (b)△ Yn 2 Xn (b)△ Yn 1 Xn (1,2)△ Yn 1 (1,2)△ Yn”, and so on. If the iterator b is very large, it’ll become “Xn (b-n)A 2 A1 1 A2 1…An+1 1 (1,2)△ Yn” (where A has lower level than “Xn (1,2)△ Yn”), then adding to be “X(n+1) (b-n)A 2 A1 1 A2 1…An+1 1 (1,2)△ Y(n+1)”, then it reduces to “(b-n-1)X(n+1) (b-n)A 2 A1 1 A2 1…An+1 1 (1,2)△ Y(n+1)”. It can further reduce to “X(n+1) X(n+1) … 2 (1,2)△ Y(n+1) 2 (1,2)△ Y(n+1)” (here some “A1 1 A2 1…Am 1″ are hidden), which can further reduce to “X(n+1) X(n+1) (1,2)△ Y(n+1) 2 (1,2)△ Y(n+1)”. So {1{1(1,2)△2}2(1,2)△2} can never be solved, and so is {1(1,2)△3}.
Now I go back to the strength of R function. It was defined at Jan 2014, so I actually have stay there approximately 3.8 years.

What is the x-separator of (_)△?
LikeLike
Generally (x)○△ is one of the x-separator of ( ____ )△, and there’re more; for example (1)(1(2)○△2)△ is another 1-separator of ( ____ )△.
LikeLike
Is (2:2){1:2} or (1:2){2:2} vaild?
LikeLike
These questions are in WDEN.
The first one, (2:2){1:2} is valid. (2:2)A searches out for a lower-leveled separator, and drops to (1:2)A, then the (1:2) expands.
The second one… Well, it hits a blind spot of the subfunction rules. Consider a simpler example, (1){2:2}. We need to check U({2:2}), D({2:2}), X({2:2}) and Y({2:2}), but there’s no rule for a non-1 number immediately after the “{“. However, if we start from the simplest forms, things like (1){2:2} never appear, because {2:2} always changes into {1:2}s, and no droppers can be generated immediately before the {2:2}.
LikeLike
If {1{…}2(2)△2} = {1{1(2)△3}2(2)△2}, {1{…}2(3)△2} = {1{1{1(3)△3}2}2(3)△2}, and {1{…}2(4)△2} = {1{1{1{1(4)△3}2}2}2(4)△2}, then {1(1,2)△3} is ill-defined.
LikeLike
No. You’re still in the DAN way.
{1(2)△3} drops to (1){1(2)△3}, then the process ends. Next process {1 (1){1(2)△3} 2(2)△2} further expands into {1 {1 …… 2(2)△2} 2(2)△2}. In DAN it’s done in one process, but in NDAN it’s done in 2 processes.
{1(3)△3} drops to (2){1(3)△3}, then the process ends. Next process {1 (2){1(3)△3} 2(3)△2} further drops to (1){1 (2){1(3)△3} 2(3)△2}, then the process ends. Next process {1 (1){1 (2){1(3)△3} 2(3)△2} 2(3)△2} expands into {1 {1 …… 2(3)△2} 2(3)△2}. In DAN it’s done in one process, but in NDAN it’s done in 3 processes.
And so on, in DAN all the dropping and one expansion are done in one process, but in NDAN each dropping or expansion costs one process. This change enables (1,2)△.
{1(1,2)△3} changes into {1(n)△2(1,2)△2}, where n is the iterator.
Next, {1(2)△2(1,2)△2} becomes (1){1(2)△2(1,2)△2}, and {1 (1){1(2)△2(1,2)△2} 2(1,2)△2} expands into {1 {1 …… 2(1,2)△2} 2(1,2)△2}; {1(3)△2(1,2)△2} becomes (2){1(3)△2(1,2)△2}, {1 (2){1(3)△2(1,2)△2} 2(1,2)△2} becomes (1){1 (2){1(3)△2(1,2)△2} 2(1,2)△2}, and {1 (1){1 (2){1(3)△2(1,2)△2} 2(1,2)△2} 2(1,2)△2} expands into {1 {1 …… 2(1,2)△2} 2(1,2)△2}; and so on, no matter what’s the iterator, {1(1,2)△3} always changes into {1 {1 …… 2(1,2)△2} 2(1,2)△2}, just as {1(1,2)△2} always changes into {1 {1 …… 2} 2}.
Seems weak, but the strength comes at {1{1(1,2)△2}2(1,2)△2}. It becomes {1{1(n)△2}2(1,2)△2} then {1 (n-1){1(n)△2} 2(1,2)△2} where n is the iterator. The next process will be a dropping or expansion, but note that (n-1){1(n)△2} always has lower level than {1 (n-1){1(n)△2} 2(1,2)△2} and { ____ (1,2)△2}. So the “outer lower-leveled separator” will always be outer than { ____ (1,2)△2}. So the { ____ (1,2)△2} remains until the inner “1{1(n)△2}2” reduces to “1”. Then {1(1,2)△2} changes into {1(N)△2} where N is the iterator now – might be much larger than the n. And that’s where the strength comes.
LikeLike
So {1{1{…}2(A)△2}2(A)△2} = {1(1)△2(A)△2}, {1(1){1(1){…}2(A)△2}2(A)△2} = {1(1){1(2)△2(A)△2}2(A)△2}, and {1(N){1(N){…}2(A)△2}2(A)△2} = {1(1){1(N+1)△2(A)△2}2(A)△2}?
LikeLike
No (except the first one). {1(1){1(N+1)△2(A)△2}2(A)△2} will be in case B2, then it changes into {1{1{…}2(A)△2}2(A)△2}.
LikeLike
NDAN found out it was stronger:
(x)○A = (1(x+1)○A2)A (where A can be any ○○○…△)
Am I right?
LikeLike
Just a little different. (x)○A and (x)(1(x+1)○A2)A work similarly, and (1(x+1)○A2)A reduces to (x)(1(x+1)○A2)A. Here A can be any separator, not only ○○○…△.
LikeLike
Now I know how (1)M works… I ask you a question.
Is s(3,3{1(2)△3}2) = s(3,3{1(1){1(2)△2}2(2)△2}2) = s(3,3{1{1(1){1(2)△2}2(2)△2}2}2) = s(3,3{1{1{1{1{…}2(2)△2}2}2(2)△2}2}2)?
LikeLike
Also…
Is s(3,3{1{1(2)△2}3}2} = s(3,3{1(1){1(2)△2}2{1(2)△2}2}2} = s(3,3{1{1{…}2{1(2)△2}2}2{1(2)△2}2}2}?
LikeLike
No.
s(3,3{1(2)△3}2)
=(B5, step 5) s(3,3(1){1(2)△3}2)
=(B2, step 4) s(3,3{1(1){1(2)△3}2(2)△2}2)
=(B2, step 5) s(3,3{1{1,2(2)△2}2(2)△2}2)
LikeLike
I have a question: When it says “(b-n-1)X(n+1) (b-n)A 2 A_1 1 A_2 1…A_n+1 1 (1,2)△ Y(n+1)” can reduce to “X(n+1) X(n+1) … 2 (1,2)△ Y(n+1) 2 (1,2)△ Y(n+1)”, where does the first “(1,2)△” in the second string come from?
LikeLike
What if you made a (..) 1-hyperseperator. And {1..2}={1,,2}={1`2}
{1..3}={1,,,2}
And {1..n}={1,,,…,2} with (n+1) ,’s
And than proceed like that. And have stuffs like {1..1..2},{1`..2},{1“..2},{1..`2},{1..“2},{1,..2},{1,,..2},{1..,2},{1..,,2},{1…2}. And the limit of that will be {1(with n .’s )2}. Where will that be in NDAN
LikeLike
Does catching function vs. strong array notation?
Many things can happen.
LikeLike
to me, {#_1{#_2}1{#_3}#_4} nearly never being the same as {#_1{#_3}#_4} seems to have came back to break this
LikeLike
how do I remove this comment
LikeLike
isn’t {1(1){1(1){1:2}2}2(1,2){1:2}2} not infinitely descending in NDAN’?
LikeLike
would {1{1{1{1(1,2){1:2}2}2}2}2(1,2){1:2}2} become {1{1(1){1(2){1(3){1:2}2}2}2}2(1,2){1:2}2} when the iterator is 3?
LikeLike